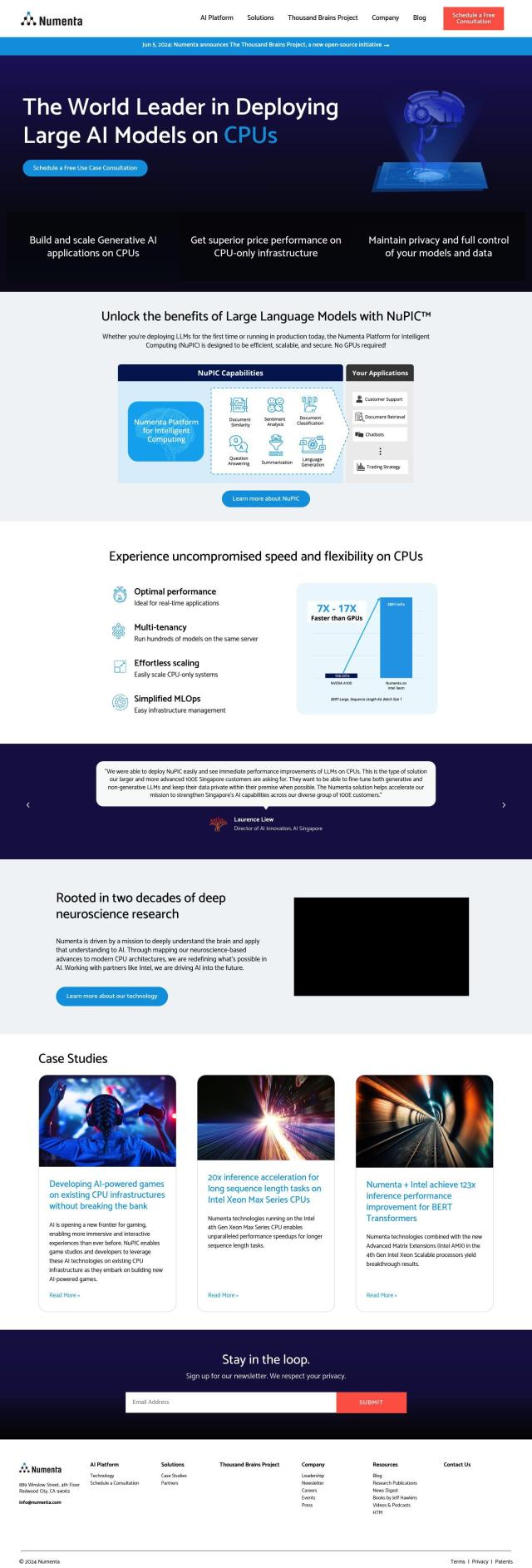
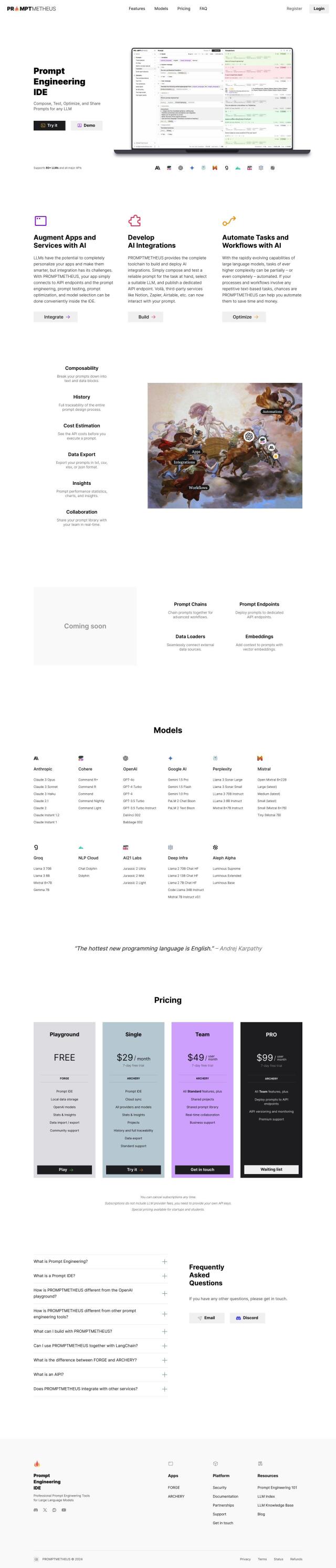
Question: I need a tool that can accelerate and optimize responses from large language models, do you know of any?


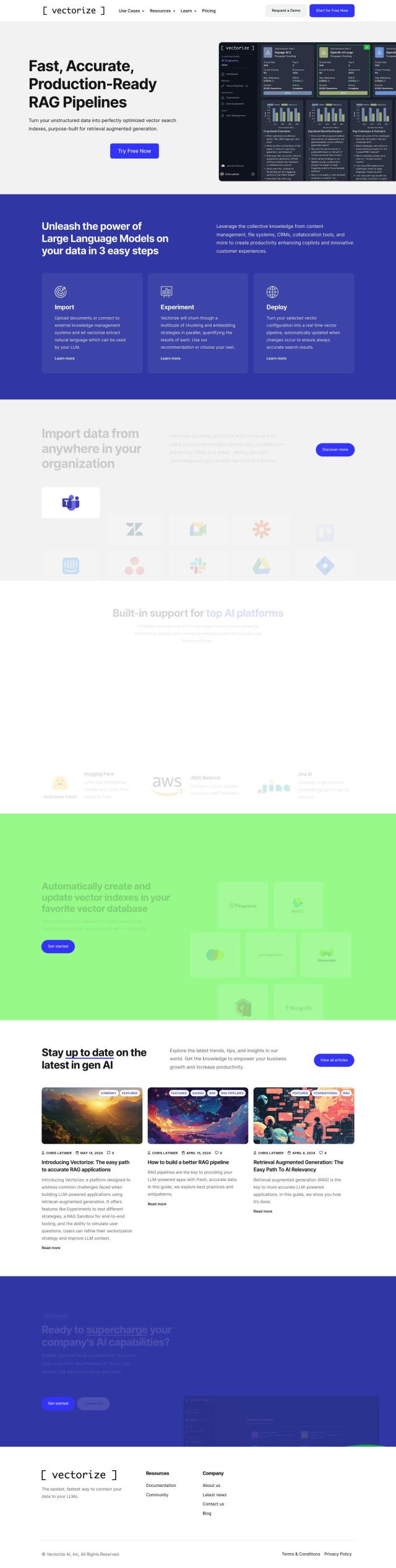
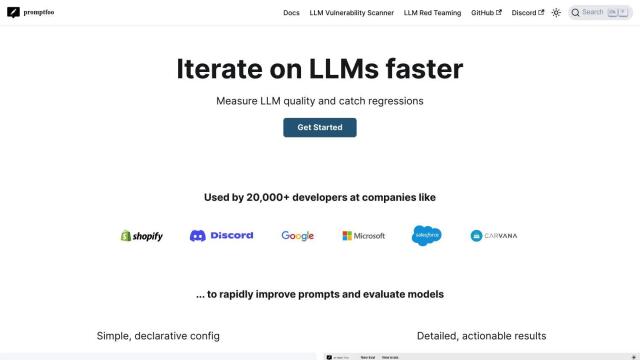
Predibase
Predibase is a foundation for developers to fine-tune and run LLMs. It supports several models, including Llama-2, Mistral and Zephyr, and has a low-cost serving foundation with free serverless inference. Predibase also has enterprise features like security and dedicated deployments with pay-by-use pricing, so it can handle small and large projects.


Klu
Another good option is Klu, which is geared for building, deploying and optimizing generative AI applications. It supports LLMs like GPT-4, Llama 2 and Mistral, and has features like prompt engineering, version control and performance monitoring. Klu is geared for teams that want to iterate rapidly based on model, prompt and user feedback, and has pricing levels for small, medium and large-scale operations.


Unify
For those who want to optimize LLM applications by sending prompts to the best available endpoint, Unify could be a good fit. The service sends prompts to multiple providers with a single API key and lets you customize routing based on factors like cost, latency and output speed. It can help you get more out of your LLM operations by improving flexibility and resource utilization, so it's a good option for optimizing LLM workflows.

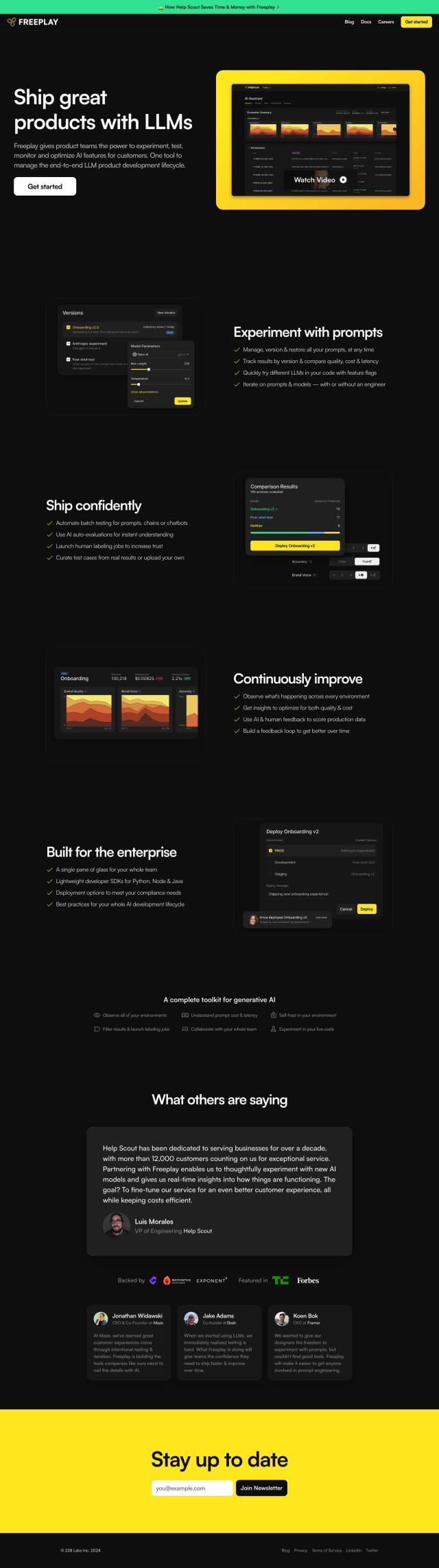
Turing
Last, Turing is a broader platform for improving LLM performance and building custom genAI products. It includes tools for evaluating and optimizing models, improving code, and integrating with agents and other tools. Turing has expertise in areas like health care, finance and retail, so it's a good option for boosting AI abilities in many industries.