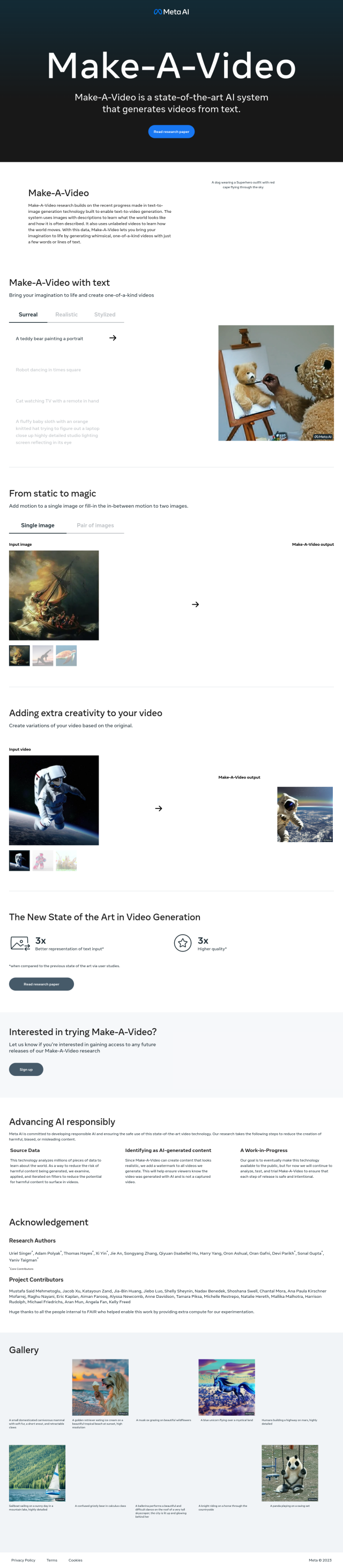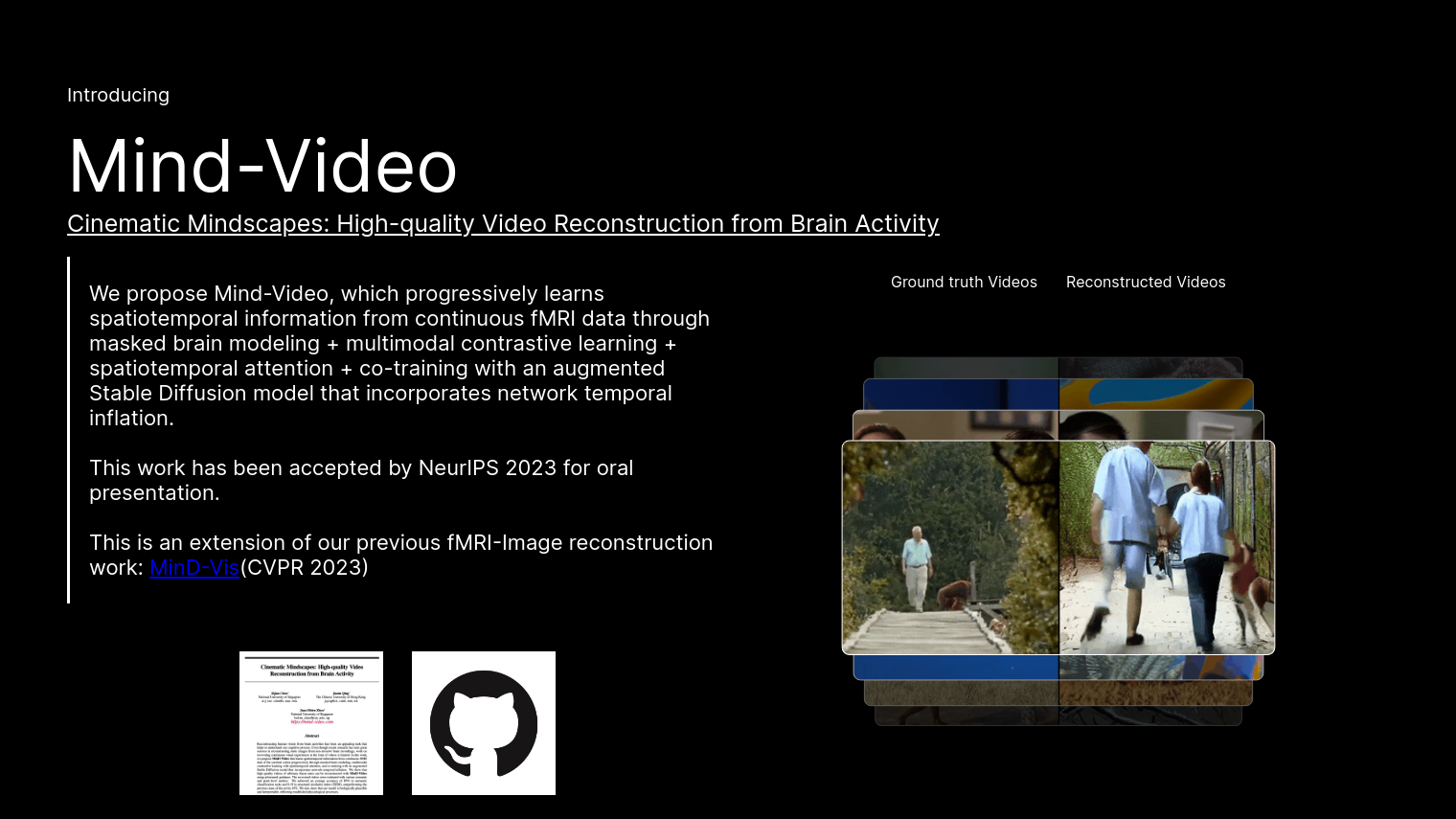
Mind-Video is an advanced model that reconstructs high-resolution videos from brain activity captured with continuous fMRI scans. The technology spans the gap between image and video brain decoding by gradually learning spatiotemporal information through masked brain modeling, multimodal contrastive learning, spatiotemporal attention and co-training with an augmented Stable Diffusion model. The ultimate goal is to reconstruct continuous visual experiences from noninvasive brain imaging data.
The technology fills three important gaps in reconstructing video:
- Time lag and accuracy: The model compensates for the lag in processing changing neural activity, so it can track the brain's real-time response.
- Pixel and semantic guidance: It uses both pixel-level and semantic-level guidance for better reconstruction.
- Scene dynamics and consistency: The augmented Stable Diffusion model preserves scene dynamics within a single fMRI frame, so the video reconstruction is consistent and stable.
Mind-Video has a two-module design that's trained separately then fine-tuned together. The first module learns general visual fMRI features through masked brain modeling and spatiotemporal attention. The second module refines those features through multimodal contrastive learning and co-training with the augmented Stable Diffusion model. The result is high-quality videos with good semantics, with a semantic metric score of 85% and a score of 0.19 on the SSIM.
The technology opens up new avenues for understanding human cognition and could lead to new developments in brain-computer interfaces, neuroimaging and neuroscience. Mind-Video's advance comes through its flexible and adaptable pipeline, gradual learning approach and biologically plausible attention analysis. You can check the website to learn more about the new approach to reconstructing brain video.
Published on June 10, 2024
Related Questions
Tool Suggestions
Analyzing Mind-Video...