Question: I need a tool that can compute semantic similarity scores between text inputs, can you recommend one?
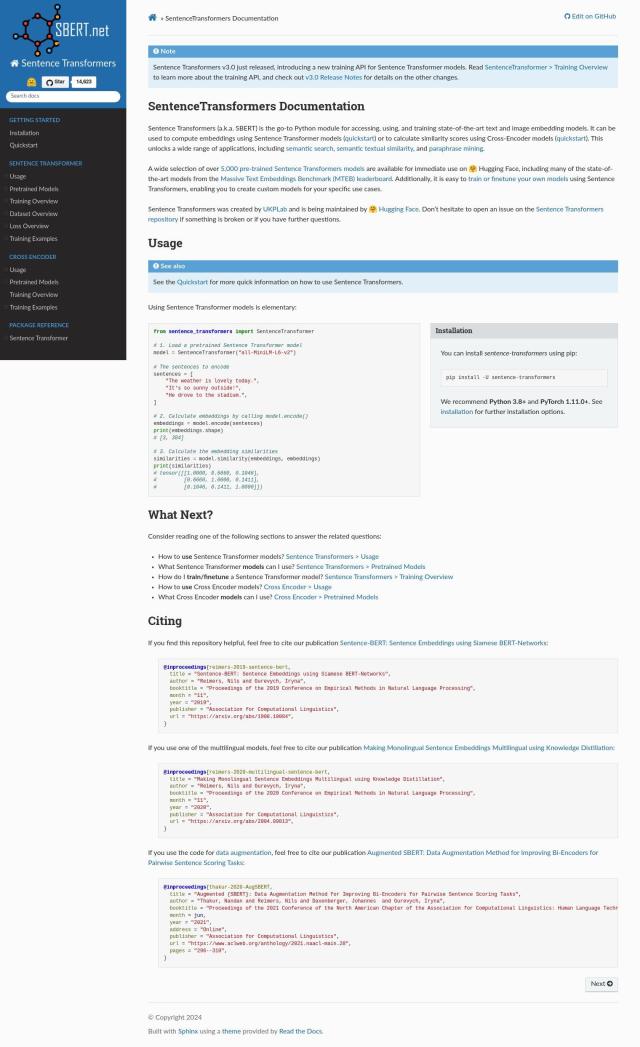
Sentence Transformers
If you need a library to compute semantic similarity scores between text inputs, Sentence Transformers is a great option. This Python library includes state-of-the-art text and image embedding models for semantic search, textual similarity, and paraphrase mining. With over 5,000 pre-trained models, it can be used to compute embeddings, semantic textual similarity, and more. The library is maintained by Hugging Face and is a great all-in-one solution for natural language processing.
Vectorize
Another option is Vectorize, which is geared for retrieval augmented generation (RAG) pipelines. It lets developers convert unstructured data into optimized vector search indexes and supports a range of chunking and embedding techniques. Vectorize has built-in connectors to services like Hugging Face and Google Vertex, and it can be updated in real time as you make changes. The service is useful for building RAG apps, such as chatbots and content generation engines, that need to be accurate.

Jina
For a more multimodal approach, you might want to look at Jina. This AI-powered information retrieval system has tools to improve search, including multimodal and bilingual embeddings, rerankers, and LLM-readers. Jina supports more than 100 languages and has auto fine-tuning for embeddings, making it a good option for many use cases. It also has open-source projects for managing multimodal data and serving large models.
Zilliz
Last, Zilliz is a fully managed vector database service designed for large-scale vector data and high-performance vector search. Based on open-source Milvus, it offers extremely fast vector retrieval speeds and high scalability up to 500 CUs. Zilliz supports a variety of use cases, including retrieval augmented generation and recommender systems, and is available on multiple clouds, including AWS, Azure and GCP. It's a good option for customers who want to scale their vector search applications without worrying about complex infrastructure.