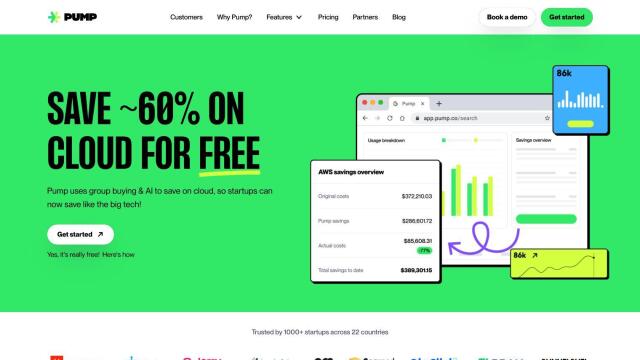
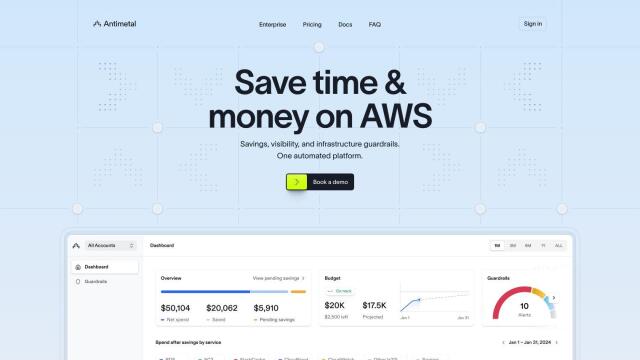
Question: How can I reduce my cloud computing costs for GPU-accelerated workloads without sacrificing performance?


Salad
Salad is a low-cost way to deploy and manage AI/ML production models on consumer GPUs around the world. It offers on-demand elasticity, multi-cloud support and several types of GPU-hungry workloads, with costs up to 90% cheaper than traditional vendors. Prices start at $0.02/hour for GTX 1650 GPUs, with discounts for bigger usage, so it's a good option for GPU computing that needs to scale and be cheap.


Anyscale
Another good option is Anyscale, which is geared for building, deploying and scaling AI software. It's got workload scheduling, cloud flexibility, intelligent instance management and GPU and CPU fractioning to make sure you're using resources efficiently. It's based on the open-source Ray framework, so it can handle a broad range of AI models, and it can cut costs by as much as 50% with spot instances, so it's a good option if you need to cut costs without sacrificing performance.


Mystic
For a serverless approach, Mystic is a low-cost, scalable way to deploy and scale machine learning models with serverless GPU inference. It works with AWS, Azure and GCP, supports multiple inference engines, and offers cost optimization options like spot instances and parallelized GPU usage. That makes it a good option for teams that focus on developing models instead of operating infrastructure, with pricing based on per-second compute usage.