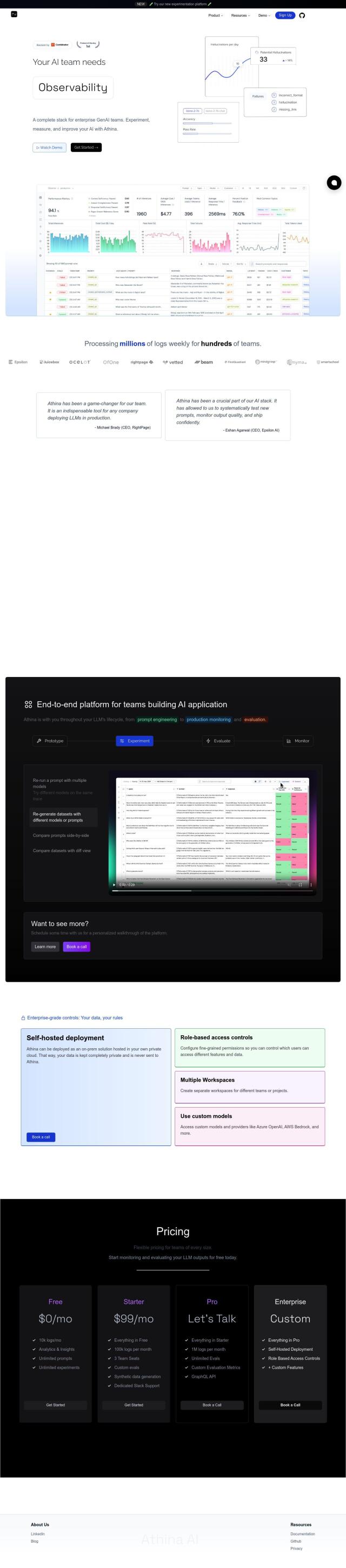
Question: How can I ensure I'm getting the best results from my large language models while balancing speed and cost?


Unify
To get the most out of large language models while keeping costs and response times under control, you might want to check out Unify. This dynamic routing service helps you optimize LLM use by sending prompts to the best available endpoint from a variety of providers with a single API key. It has a unified API, customizable routing based on factors like cost, latency and output speed, and live benchmarks updated every 10 minutes. Unify offers better accuracy, more flexibility, better resource usage and faster development, and a credit-based pricing system that means you only pay for what you use.

Kolank
Another good choice is Kolank. This interface presents a single API and browser interface to query multiple LLMs without having to obtain separate access and pay separate fees. It uses smart routing to send queries to the most accurate model and can reroute queries if a model is unavailable or slow to respond. Kolank also can save you money by sending queries to cheaper models when possible, which is a good option for developers who need to use multiple LLMs in their apps.


Predibase
If you want to fine-tune and deploy LLMs, Predibase is a good option. It lets you fine-tune open-source LLMs for specific jobs like classification and code generation with techniques like quantization and low-rank adaptation. Predibase also offers a low-cost serving infrastructure and a pay-as-you-go pricing system based on model size and dataset usage, so it's a good option for developers.


Together
Finally, Together offers a cloud platform for fast and efficient development and deployment of generative AI models. It supports a variety of models and includes optimizations like Cocktail SGD and FlashAttention 2 to accelerate AI model training and inference. Together also offers scalable inference and collaboration tools for fine-tuning and deploying models, and it promises big cost savings for companies that want to build AI into their products.