Question: Is there a way to offload AI compute tasks from my CPU and GPU to improve system responsiveness and multitasking?

Intel Movidius Vision Processing Units (VPUs)
Intel Movidius Vision Processing Units (VPUs) are tuned for computer vision and AI workloads, running at very low power while delivering high-performance deep learning inference. They can handle camera processing, computer vision and deep learning inference, for example to blur backgrounds and automatically frame subjects. Relieving your CPU and GPU of AI workloads can make your system more responsive and better at juggling multiple tasks.
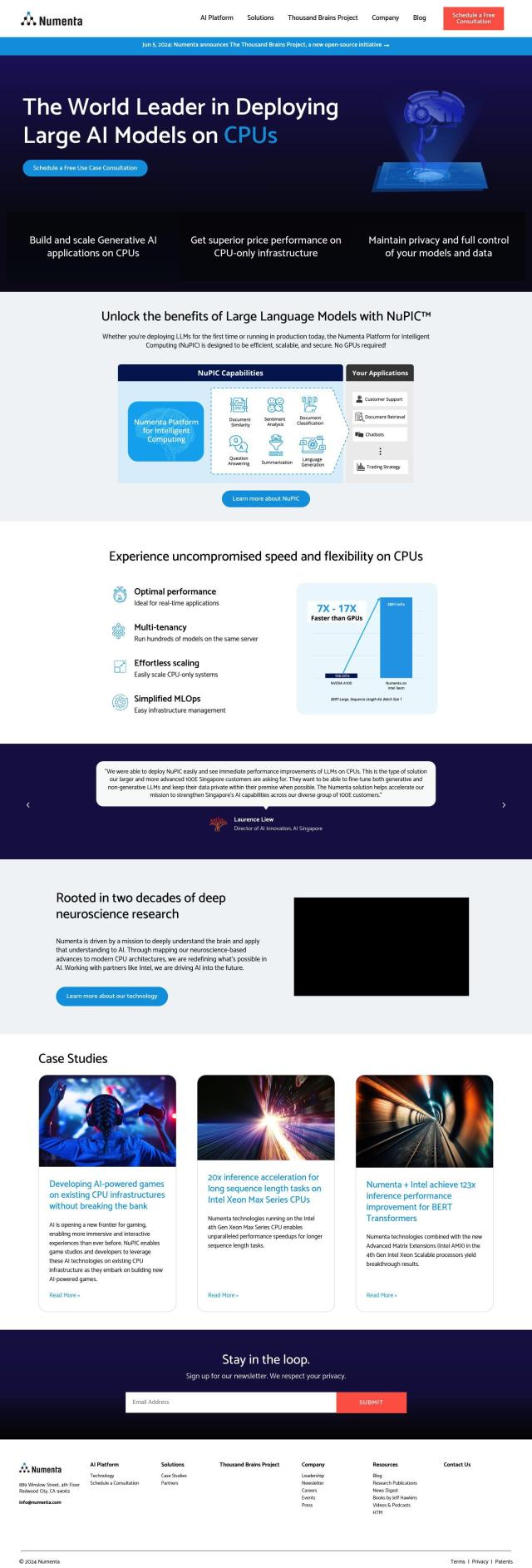
Numenta
Numenta has a platform to run large AI models on CPUs, with real-time performance optimization and easy scaling. It can fine-tune generative and non-generative LLMs, keeping data private and in control. The platform is good for industries like gaming, customer support and document retrieval that need high performance and scalability without GPUs.

Run:ai
For managing dynamic workloads and resources, Run:ai is a full-featured platform to optimize AI development by managing AI workloads and resources for best use of GPUs. It includes tools for full lifecycle support and infrastructure control, which can be useful for data scientists, MLOps engineers and DevOps teams trying to make AI development and infrastructure management easier.