Question: Do you know of a service that provides fast and customizable ML model training with dedicated hosting and API endpoints?
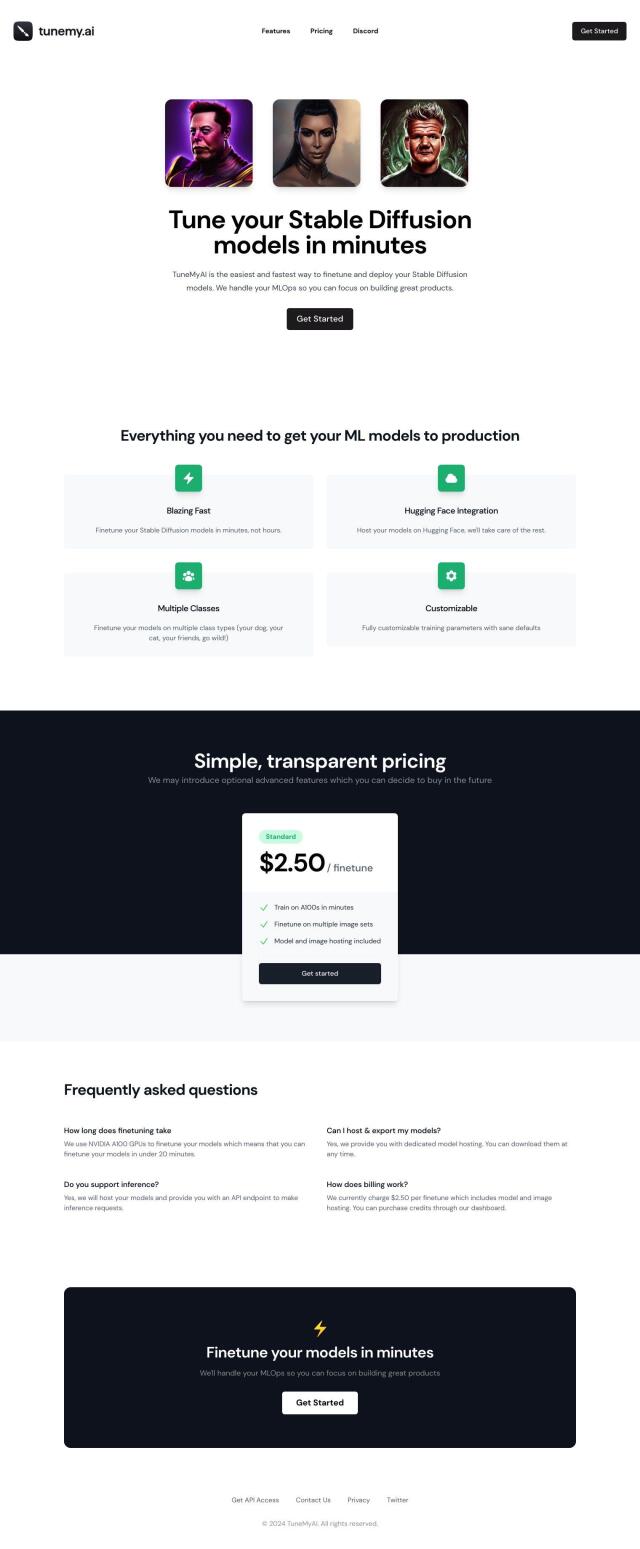
TuneMyAI
TuneMyAI is a great option for developers who need to get ML models into production fast. It offers fast finetuning with NVIDIA A100 GPUs and tight integration with Hugging Face. The service offers options for dedicated model hosting and an API endpoint for inference requests, so it's a good option for developers who want to speed up their model deployment pipeline.


Modelbit
Modelbit is another good option for deploying custom and open-source ML models to autoscaling infrastructure. It includes MLOps tools for model serving, Git integration and industry-standard security. With pricing tiers that range from light use to heavy use, including an on-demand model for cost control, Modelbit can accommodate a wide range of ML models and deployment services.


Predibase
For those who want to fine-tune and serve large language models (LLMs), Predibase is a good option for low cost and high performance. It supports a variety of models, including LLaMA-2 and Mistral, and charges on a pay-as-you-go pricing model. With features like free serverless inference and dedicated deployments, Predibase is a good option for developers who need scalable and secure LLMs.