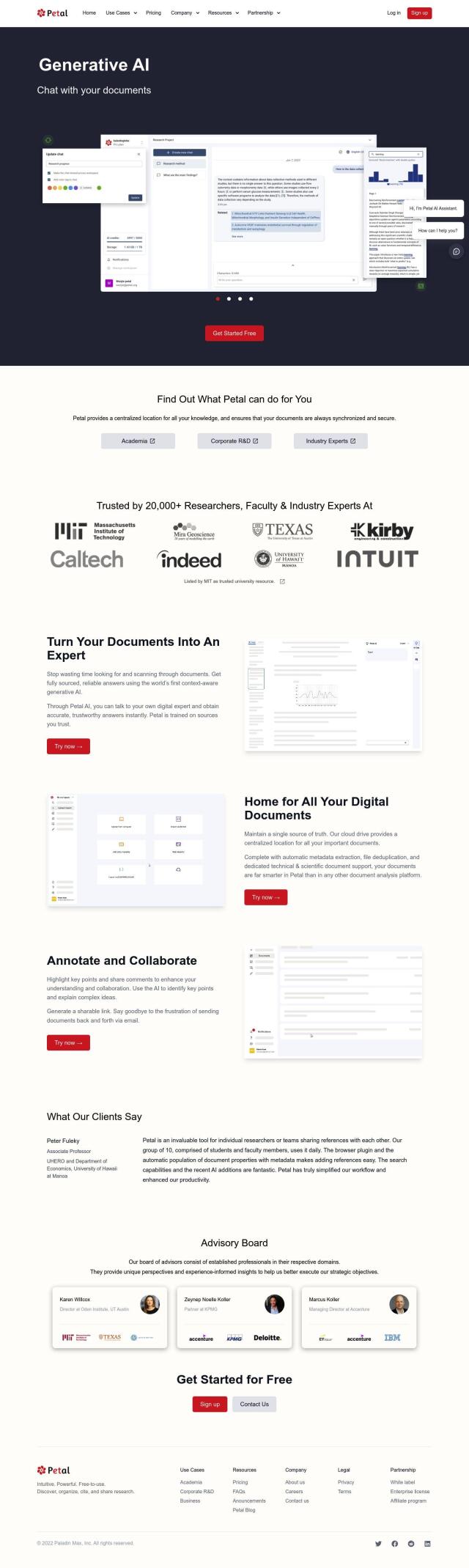
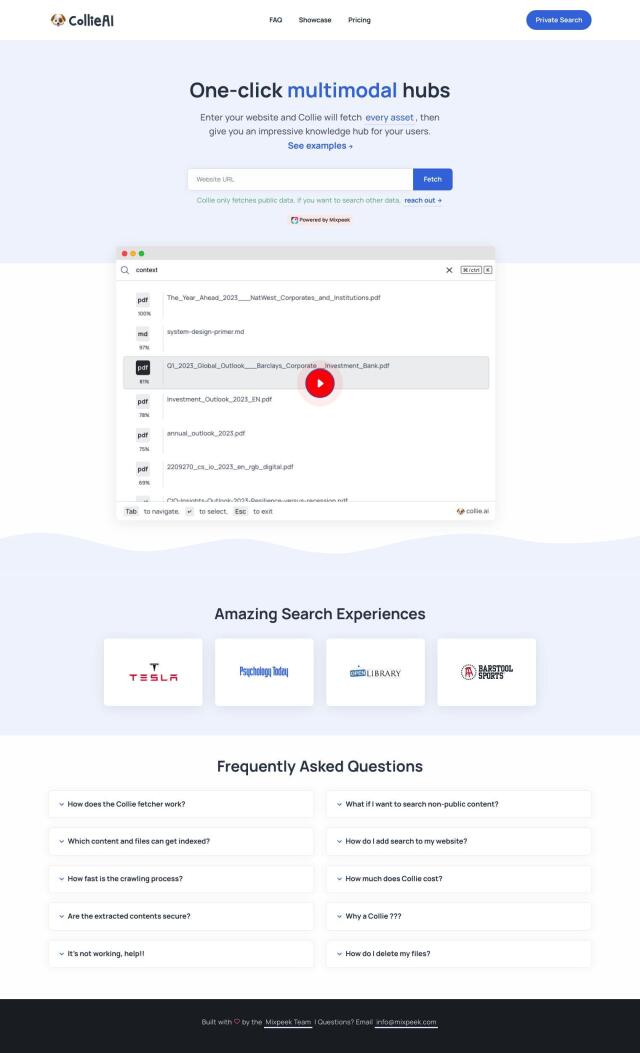
Question: I'm looking for a solution that can extract rich meta information from URLs, including article authors and recipe ratings, without scraping or parsing the data myself.
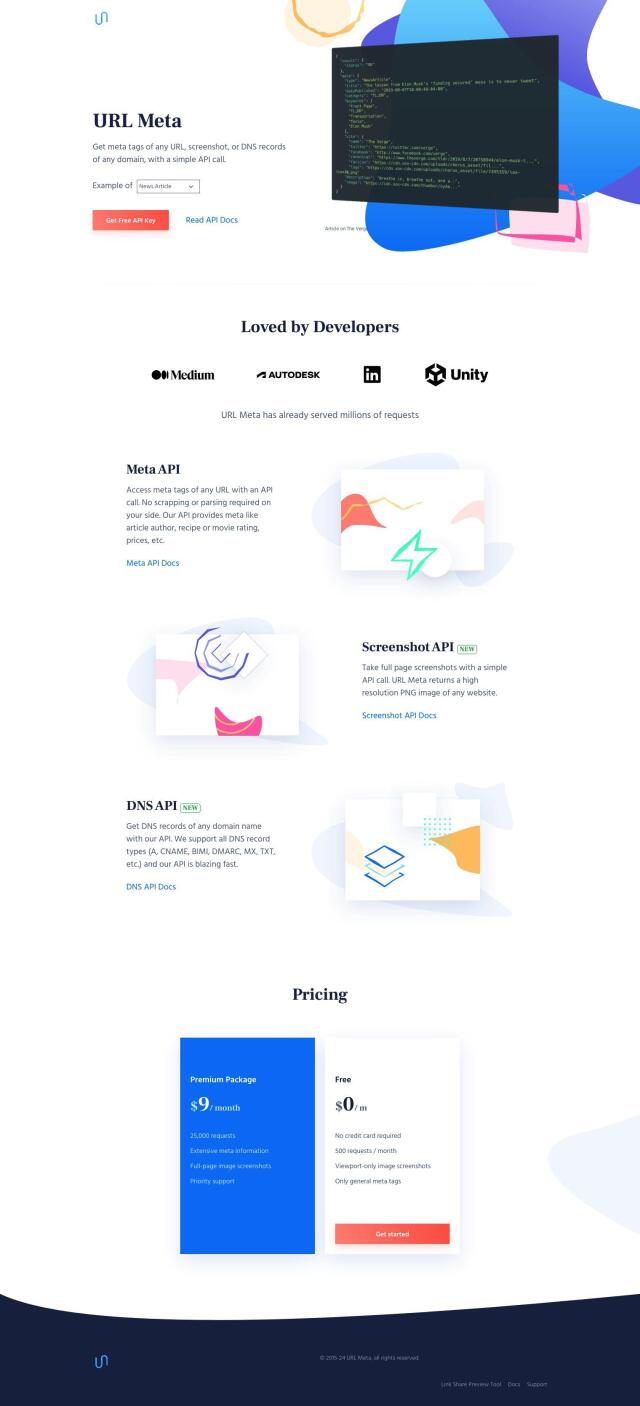
URL Meta
If you're looking for a service to extract rich meta information from URLs without scraping or parsing, URL Meta is a great option. It offers a variety of APIs for retrieving metadata, including meta tags, screenshots and DNS records, without any manual labor. The service offers rich metadata like title, description, image, favicon and logo that can be useful for content aggregation, SEO analysis and domain monitoring. The service offers a free plan with 500 requests per month and a premium plan for heavier usage.

Browse AI
Another option is Browse AI, which lets you extract specific information from websites with no programming required. The service offers a spreadsheet interface that populates automatically with extracted data and lets you schedule extractions and set up alerts when changes occur. It's not geared specifically for meta information, but its ability to extract a wide range of data points from multiple sources can be useful if you need other information, too.

Linnk AI
If you're looking for a broader information retrieval system, Linnk AI is worth a look. The service is geared for researchers and professionals who need to extract key information from complex documents and automate tedious information gathering chores. It's geared more toward extracting insights and news updates than raw meta information, but its multilingual support and ability to extract key findings from web pages could be useful in many situations.