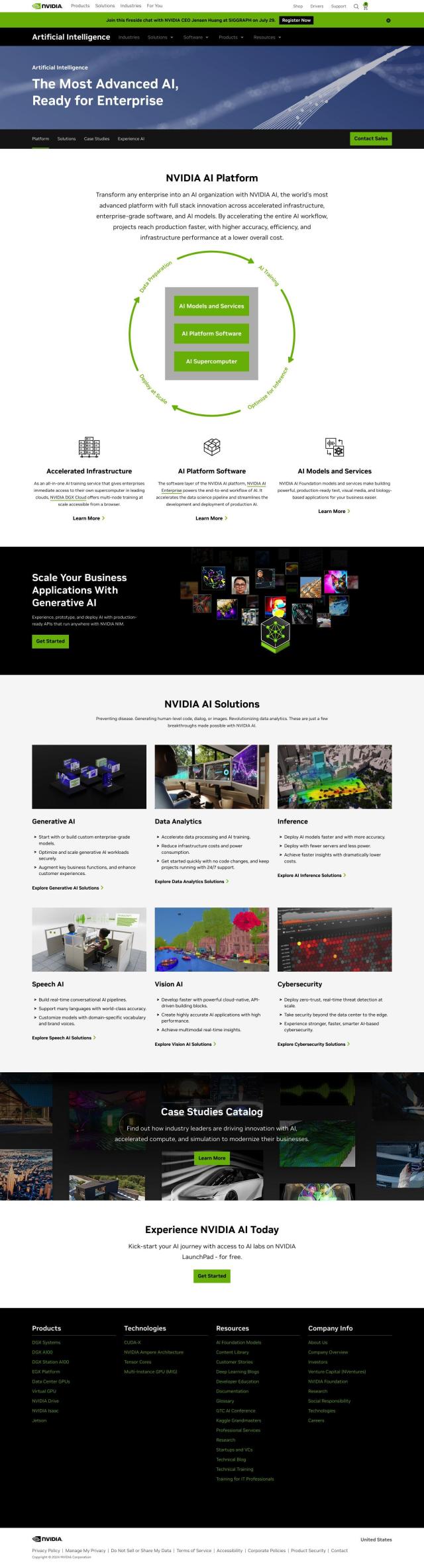
Question: I need a tool that can optimize my AI workload scheduling and minimize costs, do you know of any?


Anyscale
For scheduling AI workloads to optimize performance and cost, Anyscale is a top choice. This platform offers the highest performance and efficiency with features like workload scheduling, intelligent instance management, and heterogeneous node control. Based on the open-source Ray framework, Anyscale supports a broad range of AI models and can save up to 50% on spot instance costs. It also comes with native integrations with popular IDEs, persisted storage, and Git integration for a full developer experience.


RunPod
Another top contender is RunPod, a cloud platform for developing, training and running AI models. It offers a globally distributed GPU cloud with instant spinning up of GPU pods, serverless ML inference and job queuing. RunPod bills by the minute with no egress or ingress charges, so it's a good option. With more than 50 preconfigured templates and a variety of GPUs, the service is good for large-scale AI workloads and has a pricing model starting at $0.39 per hour.


Salad
Salad is another contender for deploying and managing AI/ML production models at scale. It offers a low-cost option by tapping into thousands of consumer GPUs around the world. With features like on-demand elasticity, multi-cloud support, and a global edge network, Salad cuts costs dramatically, with up to 90% lower costs than traditional providers. Its simple user interface and support for industry-standard tooling means it's easy to use and efficient.


Cerebrium
Last, Cerebrium offers a serverless GPU infrastructure for training and deploying machine learning models. With pay-per-use pricing, it's a lot cheaper than traditional methods. It offers real-time logging and monitoring, infrastructure as code, and a range of GPUs. Cerebrium is designed to automatically scale and can be easily integrated with your existing AWS/GCP credits or on-premise infrastructure, making it a flexible and cost-effective option.