Question: I'm looking for an AI-powered transcription service that provides secure data encryption and speaker recognition, can you suggest one?

AssemblyAI
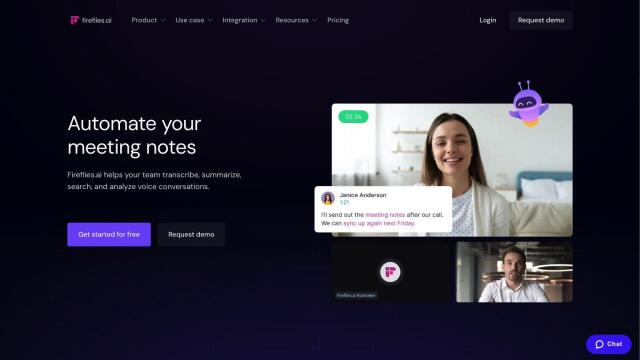
First is AssemblyAI, which offers a range of AI models for transcription, including speech-to-text, speaker identification and sentiment analysis. It's trained on 12.5 million hours of audio data, supports more than 99 languages, and has security protections like GDPR, PCI-DSS and SOC 2. It's got integration tools and a free tier for prototyping, so it's good for building new AI products.
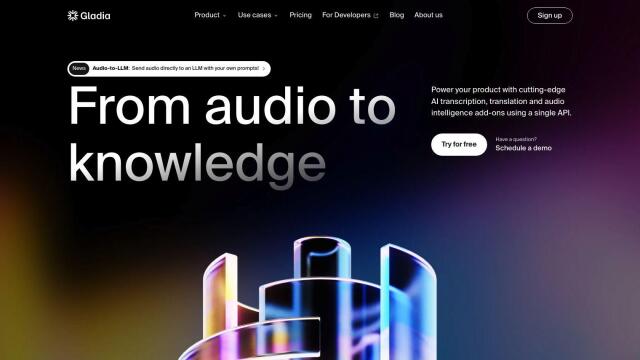
Gladia
Another option is Gladia, which converts raw audio into insights with high accuracy. Gladia offers multilingual speech-to-text in 99 languages, speaker diarization and end-to-end security for data encryption, and is designed to meet EU and US privacy regulations. It's designed for easy integration with different tech stacks, so it's good for content and media, virtual meetings and workplace collaboration.
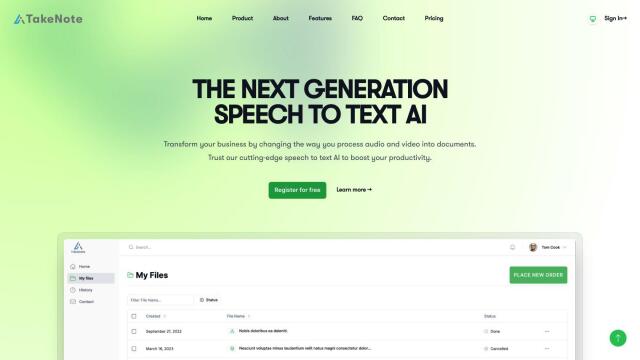
TakeNote
If you need high accuracy and high security, TakeNote offers fast and secure transcription, speaker identification and sentiment analysis. Its AI models, trained on more than 440,000 hours of data, are close to human-level accuracy, and it's deployed securely through cloud access. The company also has high data protection levels, so it's good for big data sets.