Question: I need a tool that streamlines the process of fine-tuning and deploying AI models, without requiring extensive AI expertise.


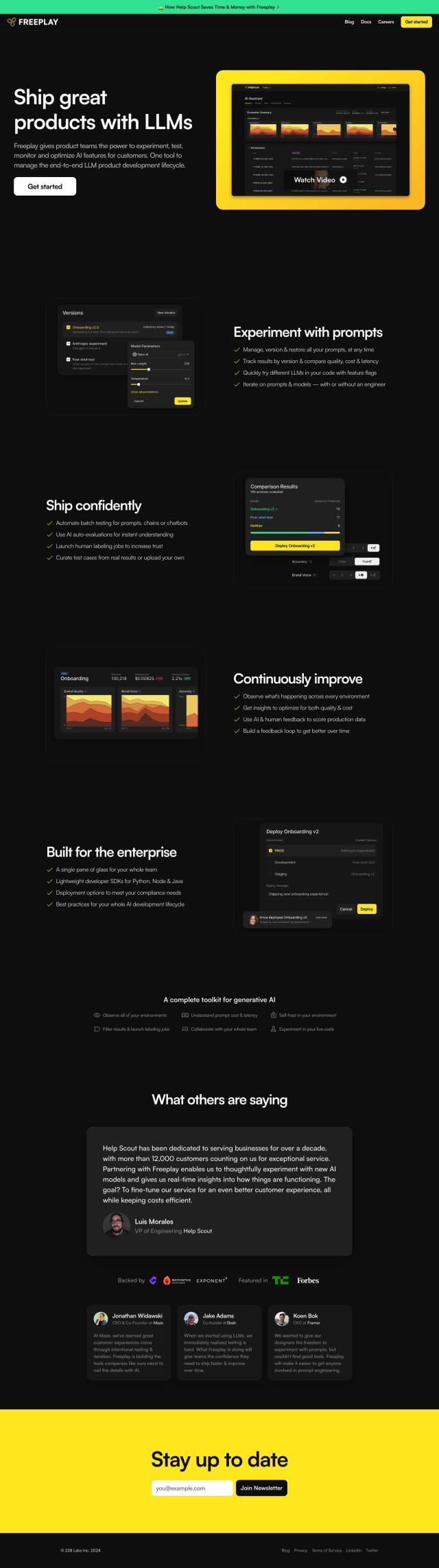
Predibase
If you're looking for a system to make fine-tuning and deployment of AI models easier without requiring a lot of AI expertise, Predibase is a good option. The service lets developers fine-tune and serve large language models (LLMs) with relative ease. It supports a variety of models, including Llama-2, Mistral and Zephyr, and has a relatively low-cost serving foundation with free serverless inference for up to 1 million tokens per day. Predibase also has enterprise-level security and dedicated support channels, making it a good choice for small and large-scale use.

MonsterGPT
Another option is MonsterGPT, which provides a chat interface for fine-tuning and deploying LLMs with minimal technical setup. You can fine-tune models for tasks like code generation, sentiment analysis and classification with a few text prompts. MonsterGPT also lets you deploy models with or without LoRA adapters and includes job management tools. It uses the MonsterAPI platform for pre-hosted generative AI APIs and charges with a subscription-based pricing model, so it's relatively affordable for many use cases.


Together
If you need a system that scales and is relatively inexpensive, Together is worth a look. This cloud platform is designed for fast and efficient development and deployment of generative AI models. It includes new optimizations like Cocktail SGD, FlashAttention 2 and Sub-quadratic model architectures, so it should work for a broad range of AI tasks. Together also has collaboration tools for fine tuning models and managing APIs, and it's cheaper than many other suppliers.


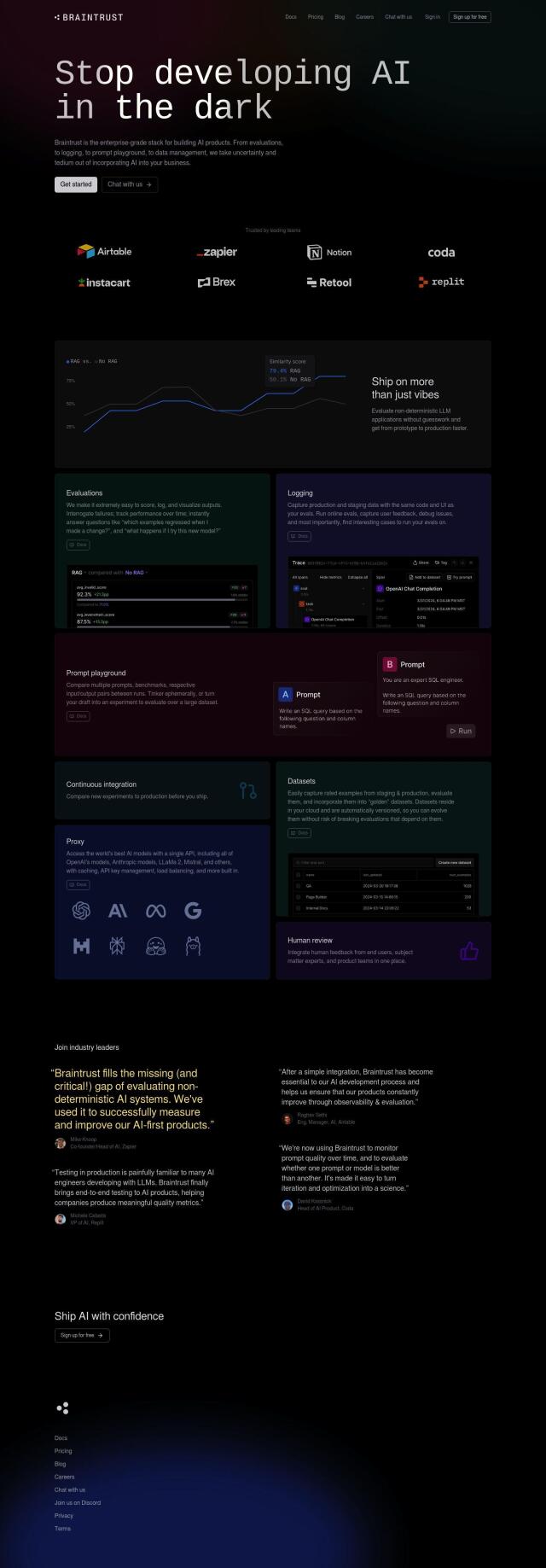
Replicate
Last, you should check out Replicate, an API-based service for deploying and scaling open-source machine learning models. It comes with a library of pre-trained models for different tasks, but you can also deploy your own with automated scaling. Replicate's simple interface and pay-by-use pricing makes it a good option for developers who want to add AI abilities without worrying about infrastructure or complicated model deployment.