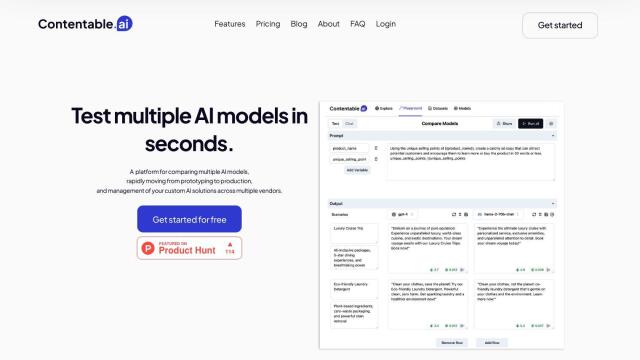
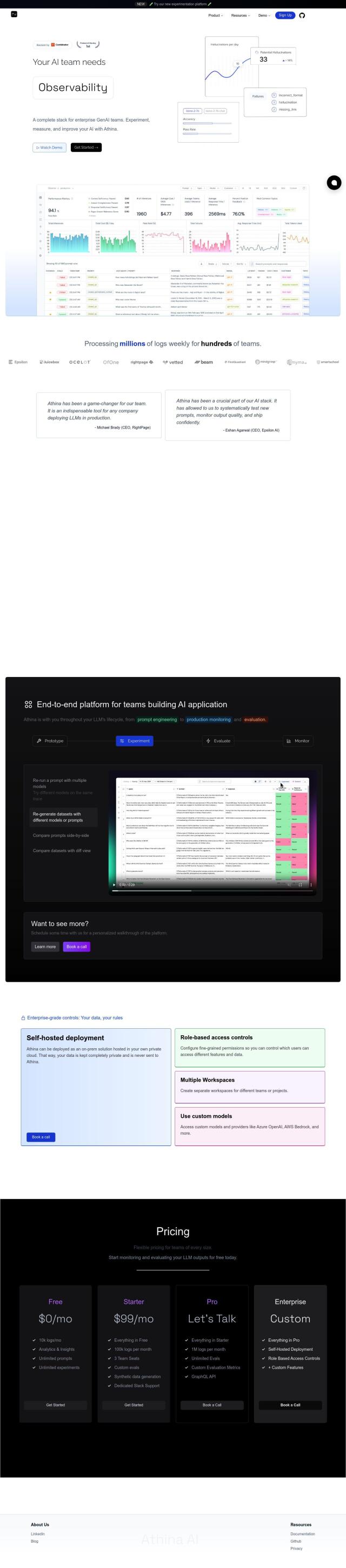
Question: I'm looking for a solution that can help me detect inconsistencies in AI-generated responses by comparing outputs from multiple models. Can you suggest one?
AnyModel
AnyModel is a good option that lets you query, compare and use multiple top AI/LLM models through a single interface. It combines results from models like Open AI ChatGPT, Google Gemini and Anthropic Claude to give you a broader perspective and to help you catch possible errors or "hallucinations." The service has a unified payment system, but planned features include the ability to add other models, summarization technology and automated analysis to check for agreement and inconsistencies.

Deepchecks
Another good option is Deepchecks, which lets developers create high-quality LLM apps by automating testing and finding problems like hallucinations and wrong answers. It uses a "Golden Set" approach for automated annotation and manual overrides to create a rich ground truth. Deepchecks lets you automate evaluation, monitor LLMs, debug them, compare versions and add custom properties for more advanced testing. It's good for ensuring LLM-based software is reliable and high quality.

HoneyHive
For a broader testing and evaluation service, check out HoneyHive. It's a single LLMOps environment where you can collaborate, test and evaluate GenAI apps. It can run automated CI tests, monitor and debug production pipelines, curate datasets and manage prompts. HoneyHive also can generate evaluation reports, benchmark results and integrate with CI/CD systems. It's good for debugging and evaluating AI models.


LastMile AI
Finally, LastMile AI is a full-stack developer platform to help engineers productionize generative AI apps. It includes features like Auto-Eval for automated hallucination detection, RAG Debugger for performance optimization and AIConfig for version control and prompt optimization. LastMile AI supports multiple AI models and has a notebook-inspired environment for prototyping and building apps, making it easier to deploy production-ready generative AI apps.